
Hey there, fellow tech enthusiasts! 👋
(I realize I always write new things on the 18th. BAHAHA!)
So, I’ve been neck-deep in training models for my school’s graduation project, and suddenly, a wild idea hit me: why not create an AI model that’s all about… well, me? 🤔
The Grand Plan
I thought, “What if I could use my dating app preferences to create an AI that understands my type?” Sounds cool, right? So, I decided to use OkCupid as my data source. Why? Because you can see everyone’s profiles clearly and even check out who you’ve liked before. Perfect!
Step 1: Data Hunting
First things first, I needed data. So, I whipped up a Python script using Selenium to automate the data collection process. The goal? Grab info on 500 profiles I liked and 500 I didn’t.
import os
import csv
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import requests
# Setup Chrome options and image save path
# Initialize the webdriver
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://www.okcupid.com/who-you-like?cf=likesIncoming")
# Scroll page to load more users
# Extract profile links
elements = driver.find_elements(By.CSS_SELECTOR, ".userrow-bucket-card-link-container .userrow-bucket-display-card a")
profile_links = [element.get_attribute("href") for element in elements]
# Open CSV file to save data
with open('okcupid_profiles.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['label', 'basic_info', 'looks_info', 'image_paths']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for link in profile_links:
try:
driver.get(link)
profile_data = {'label': 'Like'}
uuid = link.split('/')[-1].split('?')[0]
# Extract basic info
details_section = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".matchprofile-details-section--basics .matchprofile-details-text"))
).text
profile_data['basic_info'] = details_section.strip()
# Extract looks info
body_section = driver.find_element(By.CSS_SELECTOR, ".matchprofile-details-section--looks .matchprofile-details-text").text
profile_data['looks_info'] = body_section.strip()
# Click to expand profile images
profile_thumbnail = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, ".profile-thumb-container .profile-thumb-image"))
)
driver.execute_script("arguments[0].click();", profile_thumbnail)
# Wait for images to load
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".photo-overlay-images img"))
)
# Download and save images
images = driver.find_elements(By.CSS_SELECTOR, ".photo-overlay-images img")
image_paths = []
for i, img in enumerate(images):
img_src = img.get_attribute("src")
image_filename = f"{uuid}_{i}.jpeg"
image_full_path = os.path.join(image_save_path, image_filename)
# Skip existing images
if os.path.exists(image_full_path):
continue
# Download image
img_data = requests.get(img_src).content
with open(image_full_path, 'wb') as handler:
handler.write(img_data)
image_paths.append(image_full_path)
profile_data['image_paths'] = ','.join(image_paths)
# Write data to CSV
writer.writerow(profile_data)
except Exception as e:
print(f"Error processing {link}: {e}")
# Close the browser
driver.quit()Step 2: Data Cleanup
After getting the data, I had to clean it up. There were some empty fields for height, so I filled those with the average value. No big deal!
The First Attempt
Initially, I tried using all the profile info as features and threw in the profile pictures as input. Spoiler alert: it didn’t go as planned. 😅
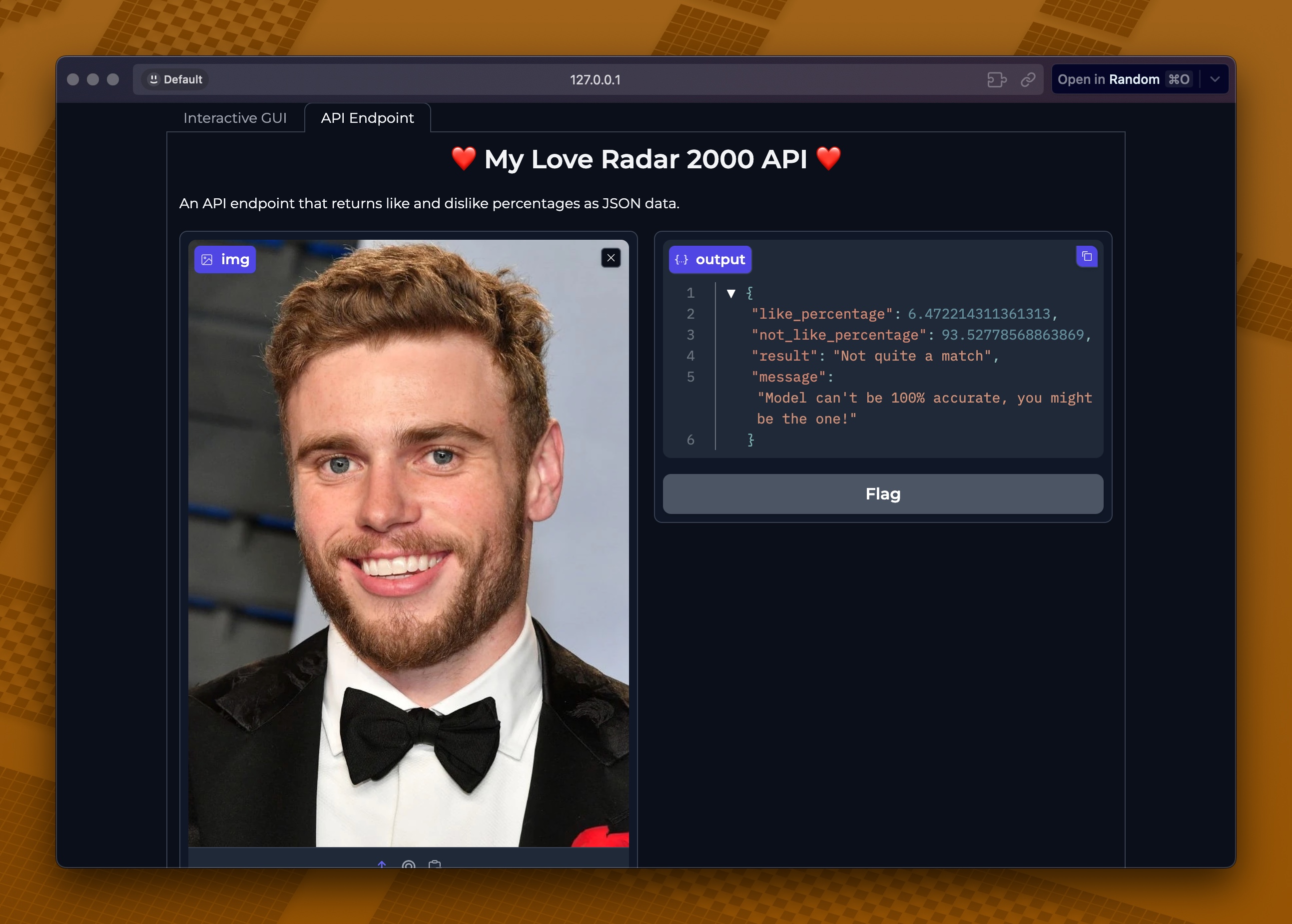
How is that possible that this man not get 100%!!?? Right? 😂
Shout out to @Gus Kenworthy!
The accuracy during training was suspiciously high. Yep, you guessed it – classic overfitting!
Take Two
For my second attempt, I decided to use other features like height and ethnicity as input for training. I used ResNet with L2 regularization as the base model. The results looked promising:
105/105 ━━━━━━━━━━━━━━━━━━━━ 92s 876ms/step - accuracy: 0.8500 - loss: 0.3787 - val_accuracy: 0.8486 - val_loss: 0.3775But something still felt off…
The Plot Twist
After some investigation, I discovered that the model was predicting “Like” for every White person in the dataset. Talk about a reality check! 😳
The Takeaway
Turns out, my preferences might be a bit too predictable, or maybe OkCupid is just flooded with gorgeous white people! Who knows? 🤷♂️
In the end, I think this idea has potential, but it’s clear that human preferences are way more complex than just looks, height, or ethnicity. There’s still a lot to explore in this space!
If you’re curious, you can check out my image-only model here: https://huggingface.co/suko/Aphrodite/
That’s all for now, folks! Remember, AI is cool, but it’s still got a long way to go before it can truly understand the complexities of human attraction. Keep experimenting and stay curious! ✌️


