
Hey there, tech enthusiasts and curious minds! 👋
So, I’ve been knee-deep in this wild ride called my university graduation project, and boy, do I have a story to tell! We’ve been on a mission to detect head movements using machine learning. Sounds simple, right? Well, buckle up, because it’s been quite the rollercoaster! 🎢

The Initial Game Plan
We started off thinking, “Hey, let’s use MediaPipe to grab some facial landmarks and train a model to figure out head movements!” Seemed straightforward enough. We were all pumped to detect tilting, turning, nodding – you name it!
Here’s a snippet of how we initially extracted facial landmarks:
import cv2
import mediapipe as mp
import pandas as pd
import os
# Initialize MediaPipe Face Mesh
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh(static_image_mode=True, max_num_faces=1, min_detection_confidence=0.5)
# Prepare DataFrame for landmarks
columns = [f"FACE_{i}_{axis}" for i in range(468) for axis in "XYZ"]
columns.append("Filename")
face_landmark_df = pd.DataFrame(columns=columns)
# Process images
for root, dirs, files in os.walk("PoseDataset"):
for file in files:
if file.startswith("."):
continue
image_path = os.path.join(root, file)
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = face_mesh.process(image_rgb)
if results.multi_face_landmarks:
landmarks_data = []
for landmark in results.multi_face_landmarks[0].landmark:
landmarks_data.extend([landmark.x, landmark.y, landmark.z])
landmarks_data.append(file)
face_landmark_df.loc[len(face_landmark_df)] = landmarks_data
# Save image with landmarks (optional)
output_path = os.path.join("FaceOutput", os.path.relpath(root, "PoseDataset"), file)
os.makedirs(os.path.dirname(output_path), exist_ok=True)
mp.solutions.drawing_utils.draw_landmarks(
image=image,
landmark_list=results.multi_face_landmarks[0],
connections=mp_face_mesh.FACEMESH_TESSELATION,
connection_drawing_spec=mp.solutions.drawing_utils.DrawingSpec(color=(0,255,0), thickness=1)
)
cv2.imwrite(output_path, image)
# Save landmarks to CSV
face_landmark_df.to_csv("face_landmarks.csv", index=False)
face_mesh.close()But here’s where it gets interesting (or frustrating, depending on how you look at it 😅):
Houston, We Have a Problem


Our model was struggling harder than me trying to wake up for an 8 AM class. It just couldn’t tell the difference between subtle movements. Tilting, turning – it was all the same to our poor, confused AI.
It almost feel like I need to crack my head to make it know I’m tilting my head. 🤦♂️
The Lightbulb Moment 💡
Then, out of nowhere, while I was probably procrastinating on TikTok, it hit me: “Why are we trying to make one model do everything? That’s like asking your cat to fetch, do your taxes, and make you coffee!”

Our Cool New Approach
Here’s what we cooked up:
- Use MediaPipe as our base model (it’s like the foundation of a house, but for faces)
- Create a bunch of smaller models, each with its own specialty (like having a different chef for each course in a fancy restaurant)
- Combine all their outputs for the final prediction (teamwork makes the dream work, right?)
It’s kind of like how Apple does their AI magic, or how LoRA works in those fancy diffusion models. We’re basically creating a boy band of AI models, each with its own special talent! 🕺🕺🕺🕺

The Secret Sauce (a.k.a. How It Actually Works)
- MediaPipe: Our facial landmark detective 🕵️
- Specialized Models
- Tilt Detective 🔍
- Turn Tracker 👀
- Nod Spotter 👍
- (and more – we got the whole squad!)
- The Mastermind: A module that takes all this info and makes the final call
Here’s a sneak peek at how we’re combining our models:
facing_model_seq = load_model('facing_direction_model.h5', compile=False)
motion_model_seq = load_model('tilt_turn_model.h5', compile=False)
up_down_model_seq = load_model('up_down_model.h5', compile=False)facing_input = Input(shape=(468 * 3,), name='facing_input')
facing_output = facing_input
for layer in facing_model_seq.layers:
facing_output = layer(facing_output)
facing_model = Model(inputs=facing_input, outputs=facing_output, name='facing_functional')shared_input = Input(shape=(468 * 3,), name='shared_input')facing_pred = facing_model(shared_input)
motion_pred = motion_model(shared_input)
up_down_pred = up_down_model(shared_input)
merged_output = Concatenate(name='combined_output')([facing_pred, motion_pred, up_down_pred])
combined_model = Model(inputs=shared_input, outputs=merged_output, name='combined_model')
combined_model.save('combined_model_with_up_down.h5')Each specialized model (tilt_model, turn_model, nod_model) focuses on its specific task, making it much more accurate at detecting subtle differences.
Did It Actually Work?
Short answer: Heck yeah! 🎉
Long answer: We saw some serious improvements:
- Better at catching those sneaky subtle movements
- Could actually tell the difference between tilting and turning (finally!)
- Worked like a charm in different lighting and head positions
Check out these comparison results:
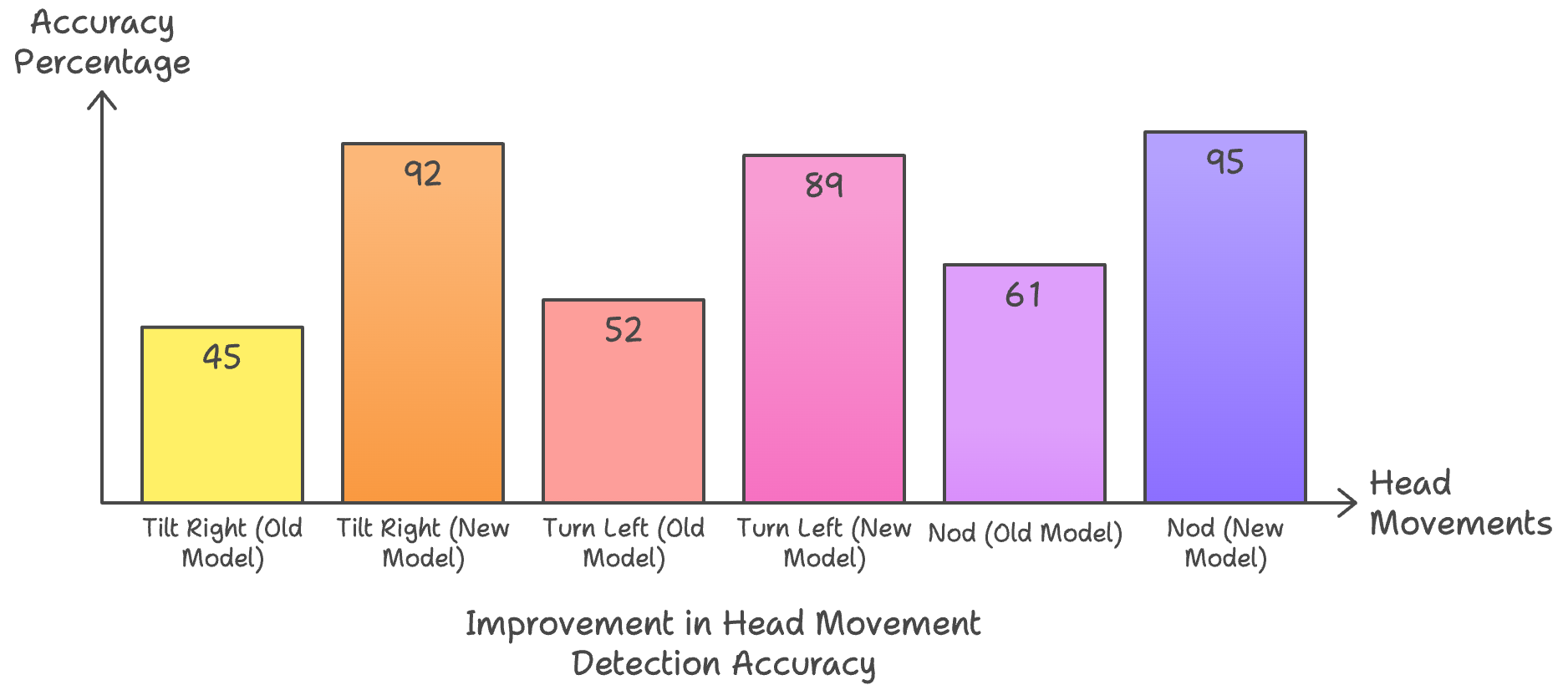
What’s Next?
Well, we’re not stopping here! We’ve got big dreams:
- Make our AI combo even smarter
- Teach it to spot even more movements (maybe even eye rolls for when I tell bad jokes)
- See if we can make it work super fast in real-time
We’re also thinking about optimizing our model for mobile devices. Imagine having this running smoothly on your smartphone! 📱✨
The Big Takeaway
Breaking down big problems into smaller, manageable chunks? Total game-changer. It’s like when you’re faced with a huge pizza – tackle it slice by slice, and before you know it, you’ve conquered the whole thing! 🍕
That’s all for now, folks! Remember, in the world of AI and machine learning, sometimes the best solution is to divide and conquer. Stay curious, keep experimenting, and who knows? Your next crazy idea might just be the next big thing! ✌️
If you’re curious, you can check out our multi-model approach here: https://huggingface.co/suko/Janus
See this original Post on my Main Blog! okuso.uk

